 La clave siempre ha estado en la proactividad, es decir, anticiparse a una degradación en la experiencia del usuario final sobre los recursos de información.
La clave siempre ha estado en la proactividad, es decir, anticiparse a una degradación en la experiencia del usuario final sobre los recursos de información.
Entre los retos que por años han tenido que enfrentar los ejecutivos de TI está el presentar la información de su operación de manera tal que los ejecutivos de la organización –que tradicionalmente no son de origen tecnócrata–, dispongan de elementos suficientes para reconocer y fomentar la importancia de la tecnología como un componente habilitador del negocio.
Han sido muchos los esfuerzos para hacer que la industria acuerde un estándar universal, primeramente a través de protocolos como la propuesta del ITU: CMIP (Common Management Information Protocol), o las del IETF SNMP (Simple Network Management Protocol) y RMON, o bien a través de plataformas donde converge la información de todos los recursos de TI, como HP Openview, IBM Tivoli, Sun Solstice o CA Infrastructure Management, por mencionar algunos.
La evolución de las herramientas de monitoreo también se ha ido alimentando mediante la llegada de protocolos más avanzados de visualización de tráfico como NetFlow, Jflow, Cflow, sflow, IPFIX o Netstream; el propósito hoy es tener una perspectiva global del “todo” para categorizar adecuadamente los eventos que afectan el desempeño de un servicio o del proceso de negocio involucrado.
Este arduo camino ha atravesado diferentes etapas como parte de su evolución y podríamos enumerarlas de la siguiente forma:
1ª Generación – Aplicaciones propietarias para monitorear dispositivos activos o inactivos
La industria ha desarrollado un sinfín de herramientas para tratar de presentar los recursos de una forma amable y en tiempo real. “Ahí, donde está la caja en rojo, eso quiere decir que el ruteador está fuera de servicio, por eso no hay conexión a la planta”, esto es lo que dice el operador de la consola de monitoreo al contralor que ha solicitado previamente un reporte al momento de mermas en las líneas de producción para un artículo que está por lanzarse al mercado.
Las herramientas de monitoreo mostraban los elementos a través de un código universal de colores:
- En verde: todo está funcionando bien;
- En amarillo: se detectó que hay algún problema temporal que no afecta la disponibilidad, sin embargo, se deben realizar ajustes para no perder la comunicación;
- En naranja: el problema se ha hecho persistente y requiere pronta atención para evitar afectaciones a la disponibilidad;
- En rojo: el dispositivo se encuentra fuera de servicio en este momento y requiere acciones inmediatas para su restablecimiento.
Parece muy sencillo comprender esta convención de colores pero usualmente el nivel de detalle es insuficiente ¿Qué pasa si el dispositivo que está en rojo sí está en funcionamiento y aún así no está realizando su función habitual?
2ª Generación – Aplicaciones de análisis de parámetros de operación a profundidad
La siguiente generación de herramientas hace lo que se llama “drill down” o “análisis a profundidad” con el fin de evaluar el estado de los componentes dentro del dispositivo (CPU, memoria, espacio de almacenamiento, paquetes enviados y recibidos, broadcast, multicast, etc.) de manera que se puedan buscar los parámetros de ajuste y que, de la misma forma en que se aprieta una tuerca en un engranaje de una máquina, los valores que se modifiquen permitan elevar los niveles de servicio del dispositivo.
Este tipo de aplicaciones se apoyan en analizadores de protocolos o “sniffers” y en elementos físicos distribuidos conocidos como “probes”, cuya función es exclusivamente la de colectar estadísticas del tráfico y que son controlados típicamente desde una consola central.
Si volvemos al mismo escenario del operador con estas nuevas posibilidades, éste sería un ejemplo de su argumento para explicar por qué no se genera el reporte: “Las estadísticas de transmisión de paquetes nos indican que la interfaz WAN 3 del ruteador está transmitiendo con altos niveles de broadcast, lo que está provocando que haya malos tiempos de respuesta y que, en consecuencia, se produzcan retransmisiones de paquetes”.
Tenemos considerablemente mayor información pero aún no hemos podido llevarla de una manera tangible a un ejecutivo del negocio para valorar conjuntamente el nivel de afectación que se esté dando.
3ª Generación – Aplicaciones de análisis punta a punta con enfoque a servicio
Con mayores niveles de información sobre los dispositivos tenemos elementos adicionales de análisis, pero aún no existen suficientes parámetros para tomar decisiones. Ahora un problema es provocado por la conjunción de varios dispositivos que participan dentro de un mismo servicio; la visión debe ser más integral y en la medida de lo posible correlacionar el comportamiento de elementos tan autónomos y dispersos como una base de datos, un servidor, un switch y hasta un enlace de comunicaciones, pero al mismo tiempo mantenerlos interdependientes porque todos participan en un mismo servicio, p. ej. una consulta de inventarios o la colocación de un pedido.
Esta generación de aplicaciones con enfoque transaccional captura ahora “flujos” de tráfico e identifica cuellos de botella y latencias a lo largo de las conexiones que existen entre los componentes de un servicio, y entrega información acerca de la salud del mismo.

Haciendo el símil con un eventual caso de la vida real, se tendría una explicación más o menos como la siguiente: “…….los niveles de uso de CPU en el servidor de base de datos están en picos que van por arriba de 80%, esto aumenta los tiempos de respuesta de la aplicación Web y entonces se genera un alto número de retransmisiones que saturan el actual ancho de banda que tenemos; esta serie de factores se reflejan en que el Servicio de Consulta de Créditos en línea sea uno de los primeros afectados….”
Esta vez hemos logrado construir un puente entre los elementos de tecnología y los servicios que están disponibles para cualquier usuario de la organización. Ahora podríamos decir que todas las partes hablan el mismo lenguaje y que las decisiones podrán ser tomadas con un enfoque de la repercusión que generan en el negocio.
4ta. Generación – Personalización de indicadores de desempeño de los procesos de negocio.
Llevando el crecimiento de las soluciones tecnológicas a los requerimientos de las organizaciones de hoy, llegamos a las vistas de “dashboard” que son indicadores que el cliente puede crear y personalizar de acuerdo a sus necesidades, además de poder seleccionar las variables que requiere correlacionar para mostrar de una manera gráfica a los tomadores de decisiones qué nivel de cumplimiento se está entregando en los procesos de negocio.
Dentro de esta generación de soluciones están aquellas que monitorean el Desempeño de Aplicaciones (APM, por sus siglas en inglés), donde convergen elementos de tecnología (“Backend”) con los sistemas de los que forman parte, y éstos con las aplicaciones que integran para llevar a cabo las transacciones que impulsan los procesos de negocio (“Frontend”). Esto, en otras palabras, es el análisis de punta a punta.
El potencial de estas herramientas permite tener información simultánea de:
-
Visibilidad de la infraestructura.
- Predicciones de desempeño.
- Modelado de escenarios (simulación y emulación).
- Análisis y planeación de capacidad.
- Funcionalidades de ajustes a las configuraciones.
- Mediciones de impacto al negocio (calidad, salud y riesgos en los servicios prestados).
- Experiencia del usuario.
Así pues, muchas de estas herramientas cuentan con modalidades como el análisis Causa-Raíz (“top-down”) que llegan hasta el ulterior elemento de tecnología que forma parte de la infraestructura del cliente; del mismo modo, a través de la integración de los elementos de la solución, se tendrán los medios para determinar cuáles son los impactos al negocio (bottom up) derivados de la falla de un recurso de TI.
Con esta incorporación se da visibilidad de punta a punta a transacciones críticas en ambientes que hoy proliferan en las organizaciones de las que usted y yo formamos parte y que involucran J2EE y .NET.
A través de este tipo de soluciones, la información ya está disponible a cualquier nivel en el contexto adecuado, y solamente se tiene que ver el indicador para mostrar el proceso de negocio afectado. Así pues, se podrán hacer afirmaciones del tipo “… el negocio está captando y atendiendo adecuadamente a nuestros clientes, y la expectativa de resultados en este momento nos permite afirmar que se cumplirán los objetivos de acuerdo a lo presupuestado…”
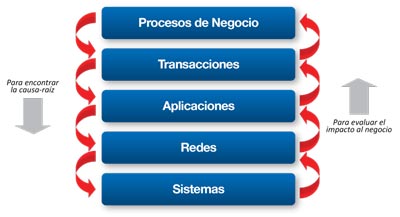
El siguiente esquema demuestra cómo se ha venido dando la evolución de las herramientas de monitoreo que hemos abordado:
Los fabricantes se han alineado a las más recientes tendencias de virtualización y cómputo en la nube, igualmente han ido sofisticando los métodos de medición con el fin de resultar lo menos intrusivos en las redes que monitorean. Al introducir “probes”, “taps” o “switches” con funcionalidades “SPAN” o “port mirroring”, y al mismo tiempo “appliances” con mucha mayor capacidad de captura para almacenar la información de semanas o inclusive meses, las posibilidades de las herramientas de monitoreo han logrado superar las expectativas.
La clave siempre ha estado en la proactividad, es decir, anticiparse a una degradación en la experiencia del usuario final sobre los recursos de información; independientemente de que los indicadores sean técnicos o enfocados a procesos de negocio. Para tener la posibilidad de “afinar” en vez de “arreglar” es fundamental que las herramientas de monitoreo se acoplen adecuadamente a la infraestructura que estarán supervisando.
¿alguna fuente de investigación acerca de la información presentada aquí en este artículo?